Validation Reporting – Early Detection of Data Design Problems
In a model-based data design environment, it is important to validate the integrity of the ‘work in progress’ as it moves through the various development phases to completion.
For example, consider a development process that populates a conceptual model with business objects, definitions, behaviors and constraints. From this model, a logical model is developed that rationalises the business objects into a data architecture composed of entities, attributes, relationships, rules and other properties. The logical model can then be ‘translated’ into one or more database architectures and instantiated in an operational data environment. This development process and sub-processes may be iterative and have some level of concurrency as well.
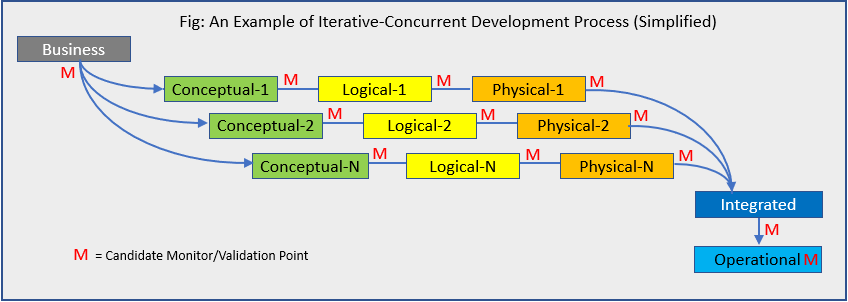
Each step in the development process may contain errors (incorrect or missing information) that either carried over from the previous step or were introduced in the current step. Numerous studies (IBM, NASA and others) emphasise that finding errors earlier in the development process substantially reduces the cost to fix those errors. Yet, development teams are faced with the additional challenges of meeting delivery schedules and other priorities. Looking at the Iterative-Concurrent process above, what are some strategies that can be used by the team to keep from ‘drowning’ in Red Ms?
First Strategy: Understand and identify which business objects and parameters, and their related data elements, are critical to the success or failure of the business. This is essential. The responsibility for this falls on the business, which is why there is an M associated with the Business step in the diagram. Business requirements are not always completely known, which then may call for an iterative development process with additional involvement of the business within each iteration. Unfortunately, not monitoring and validating early and often only increases risk, it does NOT improve the integrity of the design.
Second strategy: Understand the vulnerable steps in the development process and take corrective action. This understanding comes more from experience than a priori analysis and often relates to one or more of the following factors: Level of expertise of the development personnel, data management maturity of the organisation, and adequacy of the technology used for development.
Third strategy: Maximise use of automated processes and tools for management and technical tasks. For example, highly automated data design tools, such as erwin Data Modeler, when configured properly, significantly reduce design effort and improve quality through the extensive use of templates and algorithms. In addition, erwin Data Modeler has a rich library of model analysis and validation reports as well as the capability for creating customised reports. A very large number of object parameters, relevant to each of the development phases can be reported on easily and routinely using those reports thus helping meet the goal of validating work in progress early and often with minimal impact.
In this following example, a model validation report is configured to look for a specific error, attributes that do not have a definition. A ‘normal’ model report would report on all the attributes, both with and without definitions. In the case of larger models with many hundreds of attributes, the model validation report’s selectivity means more efficient (less effort) validation and fewer misses (higher accuracy).
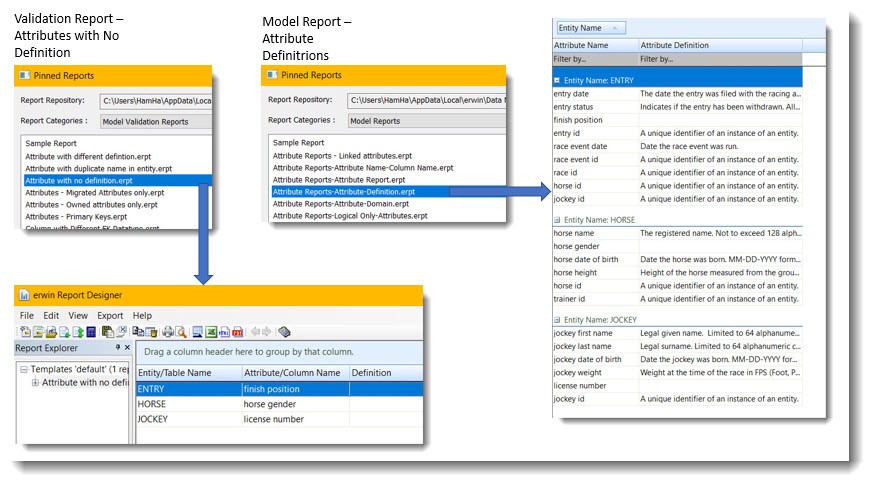
The bottom line: For most critical business applications, data designs need to be ‘proofed’ for errors.
The best strategies to maximise data design integrity and minimise development cost and schedule impacts include assuring that business objectives are understood and evaluated, appropriate design methodologies and environments are used, and validation automation is applied at critical junctures in the development process.
Check out our “erwin Data Modeler in 8 Minutes” video here to find out more about erwin Data Modeler.